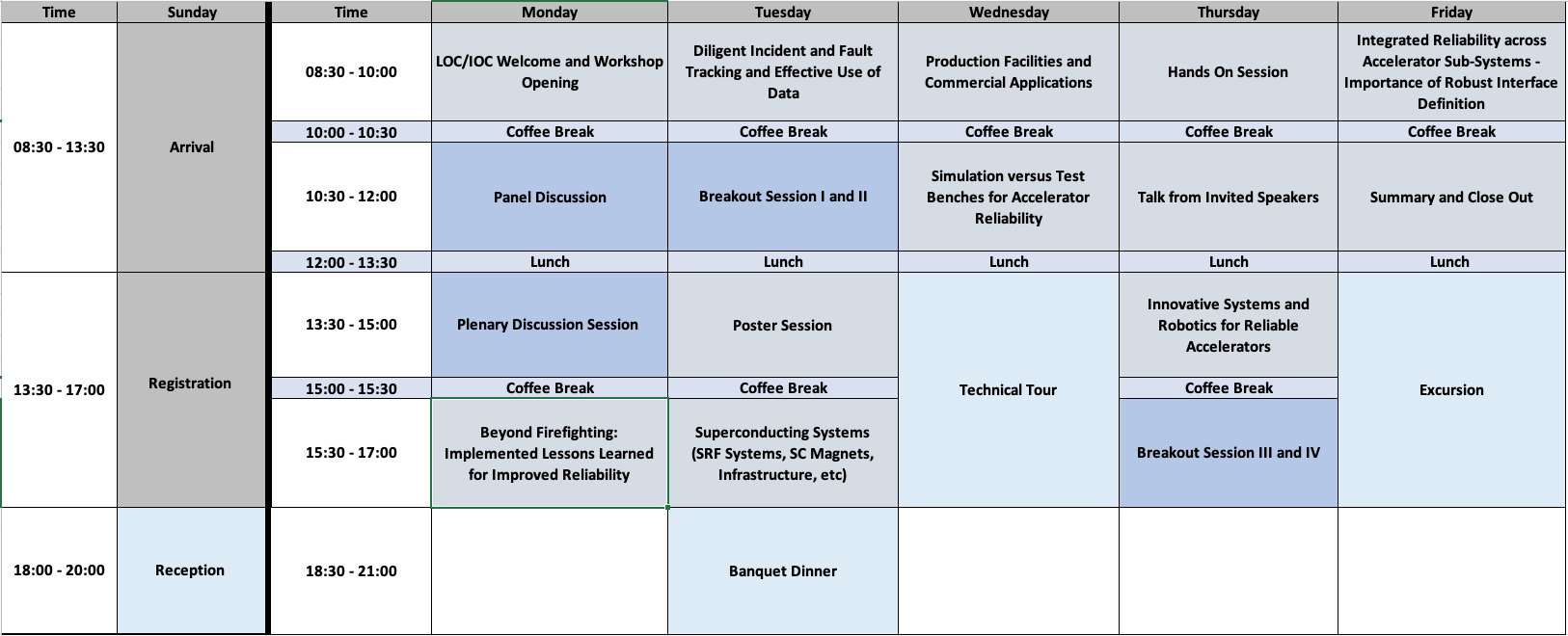
Session 1: LOC/IOC Welcome and Workshop Opening – Monday 8:30 – 10:00
Session 2: Panel Discussion – Monday – 10:30 – 12:00
This session will set the stage for the workshop through a panel discussion comparing different accelerator types and what reliability and availability mean in their operational context.
Accelerators can broadly be grouped into three categories:
- Linear accelerators used for fixed-target experiments, spallation neutron sources, or medical applications.
- Circular accelerators such as storage rings, light sources, cyclotrons, and colliders.
- Emerging accelerator concepts, including technologies such as laser-driven or plasma wakefield accelerators and energy recovery linacs.
Facilities may also differ by particle type, including electron, proton, heavy-ion, and medical ion accelerators.
Despite these differences, most accelerators share common technical systems such as magnets, power supplies, RF systems, cryogenics, vacuum systems, instrumentation, controls, protection systems, and supporting infrastructure.
Many other technologies - including medical imaging, large power systems, and magnetic confinement fusion - rely on similar engineering principles. In this broader context, accelerator reliability becomes part of a wider discipline concerned with system availability, maintainability, and operational resilience.
Participants in the Accelerator Reliability Workshop come from diverse facilities, institutes, and operational environments, but share a common objective: understanding how reliability is defined, measured, and improved.
This panel will bring together experts representing different accelerator classes to introduce key reliability concepts, metrics, and current challenges within their domains, helping participants place their own work within a broader context.
As part of this effort, the International Organizing Committee will also introduce an initiative to begin developing a community handbook that summarizes reliability practices across accelerator facilities. Participants interested in contributing will be invited to join a parallel breakout session to begin drafting the initial overview.
Session 3: Plenary Discussion – Monday 13:30 – 15:00
Accelerator facilities routinely operate under competing pressures: delivering beam, managing risk, controlling costs, and maintaining aging infrastructure. This plenary session will explore how facilities balance short-term operational needs with long-term reliability and sustainability.
The discussions may address:
- When it is appropriate to continue operating with incremental fixes versus rebuilding or replacing systems
- Lessons learned from operational experience and hindsight
- Trade-offs between availability, reliability, safety, and cost
- The role of lean methodologies in operational and upgrade decisions
- How organizational culture influences technical decision-making
This interactive session will incorporate topics submitted through the pre-workshop participant survey. (https://app.sli.do/event/1cFpbQMz4kyLgZVTrxNDDZ)

Session 4: Beyond Firefighting: Implemented Lessons Learned for Improved Reliability – Monday 15:30 – 17:00
Previous ARW workshops have shown that many facilities are highly effective at identifying technical failures and implementing rapid fixes to maintain operation. While this approach can restore functionality quickly, it often reinforces a reactive “firefighting” culture that depends heavily on a small number of highly experienced staff.
Such an approach is difficult to sustain over the long lifetimes typical of accelerator facilities. It assumes continued availability of specialized expertise and often consumes the time of key personnel who might otherwise focus on longer-term improvements.
The challenge is therefore to move beyond reactive maintenance and embed operational lessons into the way facilities design, operate, and maintain their systems.
This session will explore how lessons learned from operations can be systematically incorporated into procedures, design practices, and organizational workflows to produce measurable improvements in reliability.
Session 5: Diligent Incident and Fault Tracking and Effective Use of Data – Tuesday 8:30 – 10:00
Incident and fault tracking systems are critical tools for improving accelerator reliability. Beyond documenting downtime, these systems provide the data needed to identify trends, guide operational decisions, and support long-term improvements in facility performance.
Maintaining high-quality reliability data, however, requires sustained effort from multiple stakeholders. Clear definitions, consistent reporting practices, and cultural buy-in are essential to ensure that events are recorded with sufficient accuracy and detail.
In practice, several challenges arise. A single dataset must often support multiple users with different objectives, data collection methods may evolve over time, and the people collecting data are not always the same as those analyzing it.
This session will present practical approaches to incident and fault tracking that can be implemented at accelerator facilities, with discussion focused on:
- Effective use of data – consolidating failure information, supporting targeted reliability improvements, enabling reliability modeling, and informing predictive maintenance strategies.
- Cultural buy-in – building and sustaining engagement among operators, engineers, and management to ensure consistent and transparent reporting.
- Balancing perspectives – aligning the needs of data users with the practical constraints of those responsible for collecting the data.
- Long-term coherency – maintaining data integrity as tools, systems, and operational objectives evolve over time.
- Digital transformation – developing structured, high-quality datasets that can support emerging tools such as machine learning, automated analysis, and advanced reliability modeling.
Session 6: Breakout Sessions I and II – Tuesday 10:30 – 12:00
Session 7: Poster Session – Tuesday 13:30 – 15:00
The poster session provides an interactive forum for participants to present technical work, operational experiences, and reliability studies related to accelerator facilities.
The Organizing Committee invites poster submissions covering the design, testing, commissioning, facility operation, and maintenance of reliable accelerator systems. Posters offer an informal environment for exchanging ideas and discussing practical reliability challenges across the accelerator community.
The best poster will be selected by attendee vote and awarded a prize.
A special poster category, “Unfortunate Events: Lessons in Reliability,” continues the ARW tradition of the “disaster photo” session. Participants are encouraged to present notable reliability events—such as fires, floods, or catastrophic equipment failures—and share the resulting impacts, responses, and lessons learned.
The best poster in this special category will also be selected by attendee vote and awarded a prize.
Session 8: Superconducting Systems – Tuesday 15:30 – 17:00
Superconducting systems play a central role in many modern accelerators, and their reliability directly affects beam availability, operational stability, and maintenance requirements.
This session focuses on advances that improve the robustness and reliability of superconducting accelerator systems and their supporting RF, cryogenic, and control infrastructures.
Topics of interest include:
- SRF and magnet system architectures and their impact on reliability, fault tolerance, and operational continuity across RF, cryogenics, LLRF, and interlock systems.
- Automated diagnostics and prediction, including data-driven or machine-learning approaches for quench prediction, cavity condition monitoring, failure forecasting, and anomaly detection.
- Reliability-by-design for superconducting systems, including maintainability, requirements engineering, risk management, and strategies for ensuring quality and integration of in-kind subsystem contributions.
This session is intended for researchers and engineers developing and maintaining reliable superconducting systems for modern accelerator facilities.
Session 9: Production Facilities and Commercial Applications – Wednesday 8:30 – 10:00
Accelerators used for medical treatment, isotope production, and commercial irradiation operate under reliability constraints that differ significantly from those of research facilities. Operational metrics such as treatment throughput, isotope yield, and market demand introduce additional pressures that influence maintenance strategies, upgrade decisions, and acceptable operational risk.
This session will examine how reliability is managed in production environments where downtime directly impacts patient care or product delivery.
Topics may include:
- Balancing treatment time, verification, and quality assurance in medical accelerator operations
- Operating facilities with minimal or no scheduled maintenance windows
- Integrating new commercial systems with existing accelerator infrastructure
- Establishing equipment lifecycles, which may include end-of-life or replacement timing for aging production machines
The goal of this session is to share operational experience and identify reliability practices used in health care and commercial industry that may also benefit research accelerator facilities.
Session 10: Simulation versus Test Benches for Accelerator Reliability – Wednesday 10:30 – 12:00
Simulation and physical test benches both play important roles in establishing accelerator reliability. Simulation enables rapid, low-cost exploration of design options and operating scenarios, while test benches provide high-fidelity validation under realistic conditions.
Simulation allows teams to evaluate design concepts early, perform Monte Carlo and “what-if” analyses, and model complex physics before hardware is built. However, its predictive value depends strongly on the accuracy of assumptions and input data.
Test benches provide the experimental validation needed to confirm design assumptions, reveal unmodeled behavior, and generate high-quality data on failure modes, reliability, and component lifetime. Testing across full operational ranges or to failure, however, can be expensive and time-consuming.
This session will explore how simulation and experimental testing can be combined effectively to guide design decisions, refine reliability models, and improve confidence in system performance prior to deployment.
Session 11: Hands On Session – Thursday 8:30 – 10:00
Session 12: Invited Speakers – Thursday 10:30 – 12:00
Session 13: Innovative Systems and Robotics for Reliable Accelerators – Thursday 13:30 – 15:00
As accelerator facilities grow in scale and complexity, new technologies in automation, robotics, advanced sensing, and intelligent data systems are creating opportunities to improve reliability, safety, and operational efficiency.
This session explores how these technologies can be applied to support more dependable accelerator operation. Contributions may include advanced automation architectures and applications of open-source software, AI/ML techniques, IoT-enabled monitoring.
Within this broader automation landscape, robotics will be considered as one element of integrated reliability strategies, including telemanipulation systems, mobile robots, and automated tooling for remote intervention and maintenance. Additional capabilities may include interconnected sensors and standardized data platforms used to detect anomalies earlier; resulting in improved failure prediction, optimize maintenance implementation, and support faster decision-making during faults or recovery.
The session will also examine how open-source frameworks and shared development approaches can accelerate innovation while maintaining transparency and long-term maintainability of reliability-critical tools.
Session 14: Breakout Sessions III and IV – Thursday 15:30 – 17:00
Session 15: Integrated Reliability across accelerator sub-systems – Importance of robust interface definition – Friday 8:30 – 10:00
Modern accelerator facilities consist of complex subsystems developed by multiple teams, institutions, and in-kind contributors. In such environments, overall reliability is often determined not by individual component performance, but by the quality of the interfaces between systems.
This session focuses on how reliability is established - or lost - at subsystem boundaries.
Contributions are invited on topics including:
- Defining interface requirements early in the design process, including reliability, availability, maintainability, and operability considerations
- Verification strategies, including what to test, how to test, and when systems are ready for integrated testing
- Failure modes arising from interface mismatches, timing issues, or incomplete requirement definition
- Coordination challenges in distributed or in-kind development projects
- Maintainability and lifecycle considerations at subsystem interfaces
- Operational experience where interface definition affected commissioning, availability, or long-term reliability
A central theme is that interfaces are not owned by a single system; they require shared definition, shared accountability, and coordinated integration.
Session 16: Summary and Close Out – Friday 10:30 – 12:00